Chapter 5: Databases and Queries
A database can be defined as a collection data organised in a specific manner facilitating effective and efficient data retrieval when needed. It is a logically structured way of storing information. It can also be said that a database is an electronic system that allows data to be easily accessed, manipulated, and updated. It is one of the cornerstones of many information systems including GIS which can also be defined as a geospatial database attached to a map in digital format. The most significant benefit of database is its ability to deal with large volume of data. Having large volume of data stored in an organised way is not a new concept; however, the invention of computers has made it more efficient. Now, data can be managed efficiently and effectively by using computers.
5.1 Different Database Types
The way of handling digital data using computers is called Database Management System (DBMS). These DBMS have been evolving over time. The earliest DBMS were navigational in nature starting from flat file system to hierarchical system. These were relatively simple systems offering limited flexibility. However, these initial systems led to the development of Relational Database Management System (RDBMS) and further on to more complex and efficient systems.
5.1.1 Relational Database Management System (RDBMS)
The Relational Database Management System (RDBMS) allows users to store data in multiple tables where related data elements can relate to each other through a relationship. Each relationship has a unique name by which it is identified in the database. Each table has rows termed as “records” and columns termed as “fields”. Each field can only hold a specific type of data e.g., text, integer, decimal, or date, etc. Data type of a field should be decided at the time of creating that field. Every record of a table has a unique identifier which can demonstrate a relationship between tables. The tables can be joined together if they have a common field. RDBMS provides the flexibility of generating multiple data relations and thus can improve the data retrieval efficiencies. It ensures the atomicity, consistency, isolation, and durability (ACID) for data storing and its retrieval. It can store large data volumes. While older database management systems may allow only one user to interact at a time with the system, RDBMS allows multiple users to work simultaneously. However, conflict may arise when multiple users attempt to change the same data at the same time. This can be prevented by using locking and concurrency. Locking techniques prevent other users from accessing data while it is being updated, whereas concurrency manages the activities of multiple users invoking queries at the same time. Relational databases started in 1970s and are still the most widely accepted all over the world. While they are becoming more complex, they are becoming better, faster, and stronger.
5.1.2 Object-Oriented Database Management System (OODBMS)
An object-oriented database management system (OODBMS) is a database management system which represents data as objects. These objects inherit class and their sub-class properties. Object-Oriented Programming Languages such as Python and Java can be used to develop database objects and/or to store data as objects. There are yet not widely agreed-upon standards for OODBMS development. However, it must be consistent with the current object-oriented programming languages. The OODBMS is better suited for storing and manipulating complex data relationships providing easy solution for data extraction and manipulation across multiple tables.
5.1.3 Cloud Database Management System (CDBMS)
The digital data is growing exponentially all over the world and is becoming harder and harder to integrate and manage using traditional tools and techniques when hosted on-premises at different locations. Similarly, real time data processing is becoming the new norm for many applications as lags and delays in data delivery could have catastrophic consequences. Cyber security is another critical issue companies must deal with when hosting their data on their premises. Cloud adoption for hosting data may help to resolve some of the issues. Cloud databases provide flexibility, reliability, security, affordability and much more.
Cloud Database Management System is hosted on a virtual machine offering all cloud computing benefits such as speed, scalability, agility, and reduced costs as it is deployed, delivered, and accessed in the cloud. These databases are like traditional on-premises databases and can be used to store structured, unstructured, and semi-structured data. A cloud database can be hosted on a public or hybrid cloud environment. It can be self-managed by the owner company or can also be managed externally while being offered as database-as-a-service (DBaaS). Both scenarios have their own advantages and disadvantages. Both relational and non-relational databases can be hosted on a cloud base platform.
5.1.4 Data Warehouses
Data all over the world is growing at a very fast pace and are reaching up to petabytes. It is difficult if not impossible to run analytics on such big data using standard database techniques. Similarly, acquiring data from different data sources has always been challenging for regular users. A data warehouse provides an effective/efficient solution of this problem and allows users to aggregate data from different sources into a single, central, consistent data store. A data warehouse supports data analysis, data mining, artificial intelligence (AI), and machine learning. It also enables an organization to run powerful analytics on big data.
Data warehousing is not a new concept and has been around since 1980s as a part of business intelligence (BI) solutions and was hosted on premises. These data warehouses were designed to extract data from other sources, cleansing and preparing it to load the data, and loading and maintaining the data in a traditional relational database. However, advancements in internet technologies have allowed it to be hosted on a cloud. The cloud-based data warehouses are growing rapidly as more companies are using cloud services to reduce their on-premises data center footprint. Data analytics, visualization and presentation tools have also been added in the modern data warehouses. Enterprise Data Warehouse (EDW), Operation Data Store (ODS), and Data Mart (DM) can be three broad categories of the data warehouses.
5.2 Spatial Database
Spatial database is a database having spatial component, often in terms of coordinates, attached with the database attributes to facilitate location and geometry information of a feature. It allows users to store both vector (point, lines, polygon) and raster data in the system. Spatial database is particularly designed to represent spatial data and to process it in a spatial frame of reference. Since a spatial reference system is always required to represent the location of an object or feature, the spatial database must allow transformation of the coordinate system. The spatial databases are usually more complex as compared with the traditional databases as the relationship among spatial objects are implicit. It allows users to model relationships like “behind”, “intersect”, “overlap”, and so on. It is a building block of any geographic information system (GIS) which provides a range of spatial operations which may not be available in traditional database. The open geospatial consortium (OGC) developed standards for adding spatial functionalities to the spatial database. Development of spatial databases allows the implementation of a new set of functions in the “SELECT” statements of a data query language e.g., SQL. Spatial database uses spatial indexing system specifically designed for multidimensional ordering of the spatial data while establishing geometric relationship between different objects and features.
5.3 Data Queries
Data queries are used to store, retrieve, manipulate, and manage data stored in a database system. The “SELECT”, “UPDATE”, DELETE”, “INSERT”, “WHERE” are some of the commonly used statements in data queries. The required data can be extracted using a single criterion. Data queries especially “WHERE” class can be combined using different functions to extract required information. These queries are called multi-criteria queries.
The result of a query is a set of selected records that meet the criteria and subsequent operations will only be applied to the selected records while ignoring the rest of the records. The selected records can be imported as a new database table or can be used to perform further analysis. The “AND”, “OR”, “NOT”, and “LIKE” operator/functions are commonly used in GIS environment.
5.3.1 Intersection – “AND” Function
Intersection or “AND” function is used to extract information which satisfies all the conditions expressed in the multi-criteria query. Assume a database “T” has records of all students in an institute, “A” represents students residing in “Regina”, “B” represents students in a GIS class, and “C” represents students with grade average above 80%. A query statement:
Select students from T where Residence = “Regina AND Class = “GIS” AND Average > 80
Will return records of all the students residing in “Regina” and attending “GIS” class and having grade average of greater than 80. A graphic representation of the “AND” function using Venn diagram is given below:
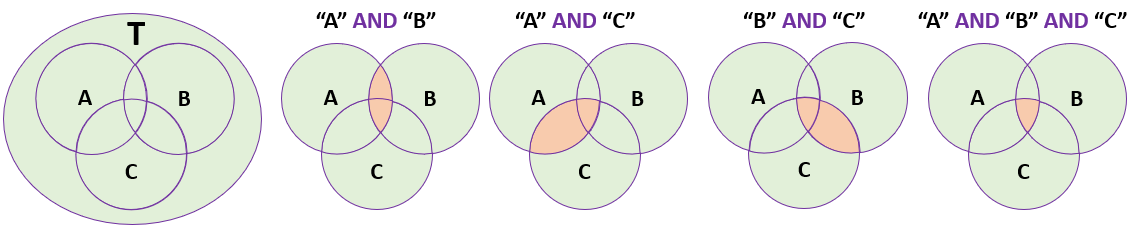
Figure 14: AND Function illustration
5.3.2 Union – “OR” Function
Union or “OR” function is used to extract information which satisfies either of the conditions expressed in the multi-criteria query. Assume a database “T” has records of all students in an institute, “A” represents students residing in “Regina”, “B” represents students in a GIS class, and “C” represents students with grade average above 80%. A query statement:
Select students from T where Residence = “Regina OR Class = “GIS” OR Average > 80
Will return records of all the students residing in “Regina” or attending “GIS” class or having grade average of greater than 80. In fact, it will return all the students who are either living in “Regina” or attending “GIS” class or having grade average above 80%.
A graphic representation of the “OR” function using Venn diagram is given below:
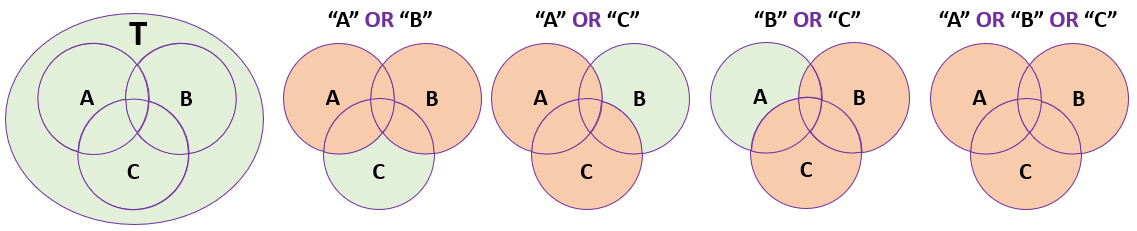
Figure 15: OR Function Illustration
5.3.3 Complement – “NOT” Function
Complement “NOT” function is used to extract information which is a part of one group but not a part of the other groups. Assume a database “T” has records of all students in an institute, “A” represents students residing in “Regina”, “B” represents students in a GIS class, and “C” represents students with grade average above 80%. A query statement:
Select students from T where Residence = “Regina NOT Class = “GIS” NOT Average > 80
Will return records of all the students residing in “Regina” but not attending “GIS” and not having grade average of greater than 80. In fact, it will return all the students living in “Regina” who are not attending “GIS” class or students not having grade average above 80%.
A graphic representation of the “OR” function using Venn diagram is given below:
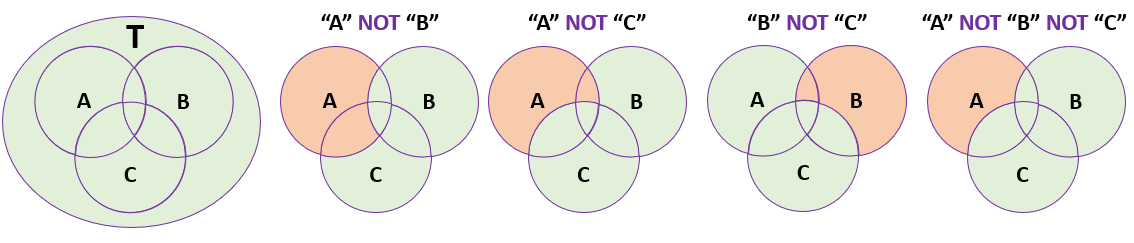
Figure 16: NOT Function Illustration
5.3.4 “LIKE” Operator
The “LIKE” operator allows users to extract information which has a partial match instead of the full match. This operator can only be applied to a “string” or “text” field of the database. It is a logical operator which requires the use of a “wildcard” character. Though there are different wildcard characters which can be used in regular a database query, most of the GIS software use “%” as a wildcard character. It is a case sensitive operator; however, some databases support the “LOWER” and “UPPER” functions to convert the attribute values to avoid case mismatch sensitivity. Some of the examples of using “LIKE” operator are given below:
“NAME” LIKE ‘%(D)%’ will find all the (D) but ignore Don or Danforth
“NAME” LIKE ‘%New %’ will find New Hampshire and New York, but not Newcastle or Kennewick
The following example demonstrates an expression to convert both the attribute value and the user input to lower case before comparing the strings for query search:
5.4 Structured Query Language (SQL)
Structured Query Language (SQL) is special purpose programming language designed for managing data stored in relational database management system (RDBMS). It can also be defined as a set of instructions used to extract, store, and manage data in a database. It allows users to create, read, update, and delete data records from a database table. SQL provides a tenderised method for interacting with a database. Since SQL can be used to perform most of the actions in a database, it is widely used by most of the RDBMS like MySQL, Informix, Oracle, MS Access, and SQL Server.
The statements of SQL are easy to read, understand, and write as they are like English statements. The syntax of SQL statements can be written as a single line text or multiline text, and it is not case sensitive. However, generally, the SQL keywords are written in upper case for easy understanding. Like other computer languages, the syntax lines are executed sequentially one after another.
